Qt сегодня стал крайне популярным SDK для разработки кросс-платформенных приложений. И это легко понять. Обеспечена поддержка всех основных операционных систем: *nix, Windows и MacOS, а мощные возможности библиотек позволяют решать даже сложные задачи минимальным количеством кода. Кроме того, организация проекта на базе pro-файла весьма удобна, поэтому я применяю ее даже для тех проектов на C/C++, которые напрямую не используют возможности Qt'а. О таком способе организации проектов мы и поговорим.
Начнем сразу с общей структуры всего проекта с последовательным разбором его элементов:
.
├── bin
│ ├── debug
│ └── release
├── build
│ ├── debug
│ └── release
├── import
├── include
├── lib.linux
├── lib.win32
├── src
│ ├── include
│ ├── MyApp
│ └── MyLib
└── tests
└── MyLibTest
На верхнем уровне у нас расположено 8 каталогов. Разберем каждый из них в отдельности.
bin/Сюда будут складываться все наши исполняемые файлы. Для режимов сборки debug/ и release/ предусмотрены собственные подкаталоги, чтобы упростить переключение между отладочной и чистовой версиями.
build/Чтобы не смешивать вспомогательные obj, moc, rcc и ui файлы с исходниками или готовыми бинарниками отведен отдельный каталог. По аналогии с bin/ он разбит на подкаталоги debug/ и release/ для соответствующих режимов сборки.
import/Сейчас довольно сложно написать более или менее серьезное приложение, в котором не задействованы никакие сторонние библиотеки. Конечно, всегда есть вариант разместить эти зависимости в системных папках и настроить к ним пути, но это решение имеет множество недостатков. Лучше всегда держать все зависимости проекта в едином каталоге, который будет помещен под управление системы контроля версий, однако это уже тема отдельной заметки. Организация этого подкаталога может быть достаточно произвольной, но я предпочитаю для каждой отдельной библиотеки выделить свой подкаталог с h-файлами, чтобы избежать возможного конфликта имен.
include/Сюда мы будем помещать все наши h-файлы, которые соответствуют открытым частям интерфейса библиотек проекта. Вообще, этот каталог можно было бы назвать не include/, а export/, но это уже дело вкуса. Он вполне может оказаться пустым, если вы пишите небольшой одноразовый проект, код которого потом не будет повторно использоваться. Но если вы решите передать кому-то ваши наработки, то при наличии такого каталога для этого будет достаточно скопировать его вместе с содержимым lib.*/, о котором мы поговорим в следующем подразделе.
тур по золотому кольцу из владивостока. гвозди купить.
lib.(linux|win32)/Чтобы не плодить глубокую вложенную иерархию подкаталогов с ветвлением по версиям операционных систем, мы просто создаем необходимые каталоги верхнего уровня с нужным суффиксом linux или win32. Я не занимаюсь разработкой приложений для MacOS, но думаю, что вы без труда добавите нужный суффикс, если это понадобится. Сюда мы будем помещать как сторонние библиотеки с разбиением на подкаталоги по аналогии с заголовочными файлами в import/, так и наши собственные библиотеки, но уже непосредственно в сам каталог lib.*/.
Кроме того, заметим, что для win32-приложений, собираемых с помощью компилятора msvc из Visual Studio, динамические библиотеки разделяются на *.lib и *.dll файлы. Первые используются во время линковки компоновщиком, а вторые непосредственно во время работы приложения и должны находиться в одном каталоге с использующим их исполняемым файлом. Возникает вопрос о том, куда поместить эти файлы для используемых сторонних библиотек. Однозначно *.lib-файлы должны лежать по путям, параллельным *.so-шникам для линукс приложений. Но куда деть *.dll-ки? Возможно несколько вариантов. Один из них заключается в том, чтобы поместить их рядом с *.lib-файлами. Но тогда их придется вручную копировать в bin/. Если же поместить их сразу в bin/, то они будут засорять сборку под другими операционными системами или с компилятором gcc, поэтому я бы не стал рекомендовать этот способ. Отдельный каталог для этого заводить тоже смысла нет, поэтому с учетом всех плюсов и минусов я сам храню *.dll-файлы рядом с *.lib-ами.
src/В нем для каждого модуля заводится отдельный подкаталог с его именем, в котором будут лежать cpp-файлы и закрытые h-файлы, которые нужны только внутри этого модуля. Не забудьте про каталог include/ верхнего уровня, в который идет на экспорт часть внешних заголовочных файлов нашего приложения. Но что делать с разделяемыми заголовочными файлами, которые нужны в нескольких наших модулях, но не имеющих такого большого значения, чтобы можно было их экспортировать? Для этого предназначен внутренний каталог src/include/. В него мы можем поместить наборы внутренних констант, объявлений классов и функций, а потом совместно использовать их в наших модулях, не нарушая инкапсуляцию.
tests/Последний по порядку, но не по значению. Тесты никогда не бывают лишними, однако нет особого смысла относиться к ним каким-то особым образом. Это тоже бинарники. Единственное отличие заключается в том, что их исходные коды должны быть логически отделены от основных, чтобы ничего не смешалось.
А теперь посмотрим на файлы, определяющие структуру проекта для утилиты qmake, на основе которых будет создан набор Makefile'ов. Как говорилось во введении, утилита qmake позволяет управлять проектами для любых C/C++ приложений, поэтому если вы пишите программу на C++, но по какой-то причине для разработки графического интерфейса применяете модули GTK+ или Win32 API, то вас не должно это останавливать от применения приведенного ниже материала.
MyProject.proГлавный pro-файл нашего проекта. В Visual Studio этот уровень называется Solution.
TEMPLATE = subdirs
SUBDIRS += \
src/MyApp \
src/MyLib
Для него используется Qt-шаблон subdirs, что означает, что наш проект будет состоять из набора модулей-подпроектов. Кто-то может решить, что нет смысла заниматься компоновкой такой многоуровневой структуры и гораздо удобнее сделать приложение на базе единственного app-проекта. Возможно, что в некоторых случаях это так, но шаблон subdirs не запрещает использование одного модуля, да и много времени вы на этом не сэкономите. Зато в дальнейшем очень часто оказывается, что одного модуля было недостаточно и все равно приходится что-то менять.
В приведенном примере у нас всего два модуля: MyApp - исполняемое приложение и MyLib - вспомогательная библиотека. Но прежде чем спуститься на уровень ниже и посмотреть на то, как устроены MyApp и MyLib, рассмотрим несколько вспомогательных pri-файлов.
common.priОбщий для всех модулей файл с определениями путей и некоторых констант, задействованных при сборке:
PROJECT_ROOT_PATH = $${PWD}/
win32: OS_SUFFIX = win32
linux-g++: OS_SUFFIX = linux
CONFIG(debug, debug|release) {
BUILD_FLAG = debug
LIB_SUFFIX = d
} else {
BUILD_FLAG = release
}
LIBS_PATH = $${PROJECT_ROOT_PATH}/lib.$${OS_SUFFIX}/
INC_PATH = $${PROJECT_ROOT_PATH}/include/
IMPORT_PATH = $${PROJECT_ROOT_PATH}/import/
BIN_PATH = $${PROJECT_ROOT_PATH}/bin/$${BUILD_FLAG}/
BUILD_PATH = $${PROJECT_ROOT_PATH}/build/$${BUILD_FLAG}/$${TARGET}/
RCC_DIR = $${BUILD_PATH}/rcc/
UI_DIR = $${BUILD_PATH}/ui/
MOC_DIR = $${BUILD_PATH}/moc/
OBJECTS_DIR = $${BUILD_PATH}/obj/
LIBS += -L$${LIBS_PATH}/
INCLUDEPATH += $${INC_PATH}/
INCLUDEPATH += $${IMPORT_PATH}/
linux-g++: QMAKE_CXXFLAGS += -std=c++11
Разберем отдельные блоки этого файла. В первой строке просто фиксируется путь к корневому каталогу проекта, относительно которого будем определять все остальные пути:
PROJECT_ROOT_PATH = $${PWD}/
Далее определяем то, под какой ОС происходит сборка, и устанавливаем соответствующим образом значение суффикса OS_SUFFIX. Значение этого суффикса будет использовано для ветвления по каталогам lib.*/.
win32: OS_SUFFIX = win32
linux-g++: OS_SUFFIX = linux
В следующем фрагменте в зависимости от режима сборки (debug или release) определяется значение BUILD_FLAG, которое будет указывать на версию используемого подкаталога в bin/ и build/:
CONFIG(debug, debug|release) {
BUILD_FLAG = debug
LIB_SUFFIX = d
} else {
BUILD_FLAG = release
}
Кроме того, определяется вспомогательный суффикс LIB_SUFFIX. Мы будем использовать его для того, чтобы к именам библиотек в отладочном режиме присоединялся символ d. За счет этого мы можем иметь единый каталог для библиотек и не допускать конфликтов имен. Например, в lib.win32/ у нас может одновременно находиться обе версии MyLib.lib и MyLibd.lib.
Далее по порядку определяются пути к библиотекам lib.*/, к открытым заголовочным файлам include/, к импортируемым заголовочным файлам import/ и путь к каталогу с бинарниками bin/:
LIBS_PATH = $${PROJECT_ROOT_PATH}/lib.$${OS_SUFFIX}/
INC_PATH = $${PROJECT_ROOT_PATH}/include/
IMPORT_PATH = $${PROJECT_ROOT_PATH}/import/
BIN_PATH = $${PROJECT_ROOT_PATH}/bin/$${BUILD_FLAG}/
Заметим, что в конце определения LIBS_PATH мы воспользовались нашим OS_SUFFIX, а в конце BIN_PATH подставили BUILD_FLAG, чтобы привести пути в соответствие с нашей начальной задумкой по ветвлению конфигурации проекта на основании версии ОС и режиму сборки.
Ниже стоит блок, который задает пути сборки для файлов ресурсов rcc, файлов графического интерфейса ui, МОК-файлов moc и объектных файлов obj:
BUILD_PATH = $${PROJECT_ROOT_PATH}/build/$${BUILD_FLAG}/$${TARGET}/
RCC_DIR = $${BUILD_PATH}/rcc/
UI_DIR = $${BUILD_PATH}/ui/
MOC_DIR = $${BUILD_PATH}/moc/
OBJECTS_DIR = $${BUILD_PATH}/obj/
Каталог сборки для каждого подпроекта будет свой. При этом его расположение зависит от режима сборки и от имени самого подпроекта, которому соответствует переменная TARGET, определенная для каждого модуля.
Поскольку библиотеки и заголовочные файлы с большой вероятностью будут использоваться многими модулями совместно, то мы определяем ключевые переменные LIBS и INCLUDEPATH тоже в общем файле:
LIBS += -L$${LIBS_PATH}/
INCLUDEPATH += $${INC_PATH}/
INCLUDEPATH += $${IMPORT_PATH}/
Ключ -L перед $${LIBS_PATH} означает, что мы определяем каталог, в котором компоновщик должен искать библиотеки в процессе сборки. А чтобы добавить конкретную библиотеку, нужно использовать ключ -l. Например:
LIBS += -lMyLibПри этом, как видно из примера, расширение файла указывать не требуется, поскольку в разных ОС и для разных компиляторов оно может быть разным.
Последняя строка не является обязательной для сборки, но если вы хотите задействовать в вашем приложении возможности C++11, то имеет смысл ее не забыть:
linux-g++: QMAKE_CXXFLAGS += -std=c++11
app.priМежду всеми исполняемыми модулями есть что-то общее. Определим соответствующие настройки сборки в pri-файле:
DA88.
DESTDIR = $${BIN_PATH}/
linux-g++: QMAKE_LFLAGS += -Wl,--rpath=\\\$\$ORIGIN/../../lib.$${OS_SUFFIX}/
Переменная DESTDIR указывает путь, в который будет помещен готовый исполняемый файл. Это окажется либо bin/debug/, либо bin/release/.
В следующей строке определяется путь поиска динамических библиотек по умолчанию. В Windows он работать не будет. А в Linux позволяет упростить запуск скомпонованного исполняемого файла. Если опустить эту строку, то приложение все равно можно будет запустить, но тогда:
/etc/ld.so.conf;LD_LIBRARY_PATH.Вариант с LD_LIBRARY_PATH является самым простым, поскольку в этом случае вам не нужны root-права в системе. Удобно использовать для этого скрипт следующего вида:
#!/bin/sh
export LD_LIBRARY_PATH=../../lib.linux/:../../lib.linux/import_dir/
./MyApp
lib.priКак и для исполняемых файлов, для библиотек тоже удобно определить общий pri-файл:
DESTDIR = $${LIBS_PATH}/
win32: DLLDESTDIR = $${BIN_PATH}/
VERSION = 1.0.0
QMAKE_TARGET_COPYRIGHT = (c) My Company Name
Переменная DESTDIR имеет такой же смысл, как и в app.pri.
Следующая строка будет работать только в Windows. Она удобна тем, что позволяет автоматически скопировать все *.dll-файлы в каталог к исполняемым файлам.
Определения переменных в конце указывают информацию о версии библиотеки и ваш копирайт. Например, в Linux при значении VERSION = 2.0.1 вы получите библиотеки с именем вида libMyLib.so.2.0.1. Но копирайт будет отображаться только в Windows, при этом имя библиотек будет выглядеть следующим образом: MyLib2.dll, а в свойствах вы увидите что-то подобное:
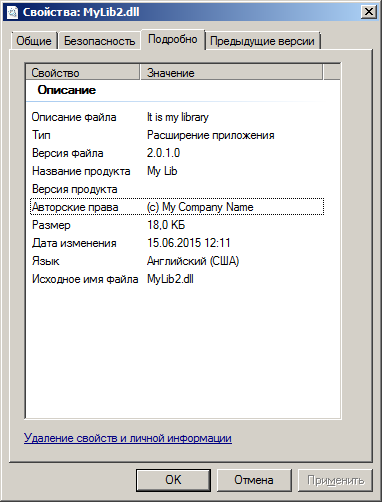
Заметим, что может появиться необходимость определить переменную VERSION для каждой библиотеки отдельно, если вы хотите иметь тонкий контроль над этим значением. Но я считаю, что версии всех библиотек в рамках одного проекта должны совпадать и не имеет смысла вносить излишние различия.
Кроме того, обратите внимание, что в описании библиотеки указаны не только "Авторские права", но и "Описание файла" с "Названием продукта". Эти два значения уже имеет смысл определять для каждой библиотеки в отдельности.
MyApp.proПришло время посмотреть на содержимое файла конкретного модуля:
QT += core gui
TARGET = MyApp
TEMPLATE = app
SOURCES += main.cpp\
mainwindow.cpp
HEADERS += mainwindow.h
FORMS += mainwindow.ui
include( ../../common.pri )
include( ../../app.pri )
LIBS += -lMyLib$${LIB_SUFFIX}
Содержимое этого файла достаточно типично для Qt-проектов и не вызывает особых сложностей. Большую его часть может легко создать QtCreator, поэтому рассмотрим лишь последние 3 строки. Директива include позволяет включить содержимое наших pri-файлов, объявленных ранее. В зависимости от версии утилиты qmake мы могли бы вынести команду include( ../../common.pri ) в начало файла app.pri, чтобы уменьшить количество кода, поэтому проверьте, будет ли работать такой вариант у вас. В последней строке мы просто подключаем наш модуль MyLib с суффиксом LIB_SUFFIX. Заметим, что путь поиска библиотек компоновщиком уже был определен в common.pri, поэтому здесь нам его дублировать не нужно.
MyLib.proinclude( ../../common.pri )
include( ../../lib.pri )
QT += core gui
TARGET = MyLib$${LIB_SUFFIX}
TEMPLATE = lib
DEFINES += MYLIB_LIBRARY
SOURCES += mylib.cpp
HEADERS += ../../include/mylib.h \
../../include/mylib_global.h
win32 {
QMAKE_TARGET_PRODUCT = My Lib
QMAKE_TARGET_DESCRIPTION = It is my library
}
Здесь тоже все достаточно стандартно, но обратим внимание на следующие моменты:
TARGET задействовать суффикс LIB_SUFFIX из common.pri подключаем его заранее в самом начале;include/;QMAKE_TARGET_PRODUCT и QMAKE_TARGET_DESCRIPTION.Вот мы и рассмотрели способ организации проекта на C++. Очевидно, что нет особой необходимости пользоваться утилитой qmake для того, чтобы ей следовать. Кроме того, с минимальными изменениями она вполне может подойти и для проектов на других языках программирования. Однако следует учитывать, что не существует идеального способа организации проекта, поэтому вы можете взять предложенный мной вариант в качестве основы и адаптировать его под свои нужды.
Anonymous:
А можно где-то посмотреть исходный код проекта с описанной в статье структурой?
В качестве примера можете посмотреть проект из статьи про разработку простого чата.
Представляется более рациональным вместо:
include( ../../common.pri )
include( ../../lib.pri )
использовать универсальный способ записи:
include($${_PRO_FILE_PWD_}/common.pri)
include($${_PRO_FILE_PWD_}/lib.pri)
где _PRO_FILE_PWD_ - встроенная переменная, которая содержит путь к каталогу самого первого файла, который начал обрабатывать qmake, т.е. в нашем случае к каталогу MyProject.pro файла. С ее помощью всегда можно вычислить абсолютный путь к файлам вроде common.pri и lib.pri. (http://blog.mgsxx.com/?p=1781). В приведенной записи эти файлы у нас расположены в одном каталоге с главным pro-файлом нашего проекта. В этом случае мы избавляемся от необходимости следить за структурой и глубиной вложенности используемых каталогов нашего проекта.
Здравствуйте, russich. Большое спасибо за такие развернутые комментарии.
Мне очень понравилась предложенная в статье структура проектов. Очень основательный подход к решению отнюдь не второстепенного вопроса организации проектов. Можно конечно же довольствоваться проектами, созданными по умолчанию мастером и валить в общую кучу билды всех своих проектов… Но с увеличением числа созданных проектов и решенных задач в этой файлопомойке все труднее будет ориентироваться самому автору. О сторонних разработчиках и вовсе не может быть речи. Не будет нормального решения для повторного использования уже разработанного кода. Четкая структуризация всех проектов - залог отсутствия дублирования кода и минимальных затрат на поиск необходимого модуля в будущем не только автором, но и его коллегами. Полная аналогия со структуризацией книг в библиотеке. Если у какого-либо буратины в личной библиотеке кроме букваря и пары рекламных буклетов ничего нет - нафига ему какая-то каталогизация? А если этот же буратина зайдет в любую большую библиотеку - то без каталогизации там делать нечего… Аналогичную каталогизацию программного кода предлагает программистам классовая методика в программировании. Это один из побудительных мотивов создания объектного подхода. Наследование и инкапсуляция являются хорошими инструментами для упорядочивания большого количества фрагментов программного кода. А хорошая структура проектов создает практическую реализацию систематизации разработки программного кода.
В нашем случае объектный подход при создании структуры взаимосвязанных проектов и предложен в данной статье. Потому что объектный подход это не только кодинг, с использованием правил записи объектноориентированного (ОО) языка, это прежде всего способность мыслить объектноориентированными категориями. Можно в синтаксисе ОО языка на деле писать код, который по своей сути не потянет даже на структурный подход…
И в заключении поста хочу добавить немного по существу тематики данной статьи. DEPENDPATH - эта переменная предназначена для оптимизации работы утилиты make (http://blog.mgsxx.com/?p=2070). Она призвана разделить стабильные и изменяемые файлы, чтобы не включать в список зависимостей стабильные файлы и тем самым сократить работу make. Поэтому при составлении списка путей включаемых заголовочных файлов можно сделать так:
оригинал:
LIBS += -L$${LIBS_PATH}/
INCLUDEPATH += $${INC_PATH}/
INCLUDEPATH += $${IMPORT_PATH}/
По условиям, оговоренным в статье, IMPORT_PATH - каталог с заголовочными файлами сторонних библиотек (import/), INC_PATH - каталог с внешними заголовочными файлами нашего проекта (include/). Следовательно в список построения зависимостей надо будет включать только заголовочные файлы из каталога INC_PATH. В итоге с учетом сказанного получим:
LIBS += -L$${LIBS_PATH}/
DEPENDPATH += $${INC_PATH}/
INCLUDEPATH += $${INC_PATH}/
INCLUDEPATH += $${IMPORT_PATH}/
Переменную DEPENDPATH имеет смысл использовать только при CONFIG -= depend_includepath. Но как замечено в http://blog.mgsxx.com/?p=2070 "практика показала, что от такой оптимизации больше вреда, чем пользы." Так что решение об использовании данной feature - дело вкуса разработчика…
Статья хорошая, но как уже было сказано не хватает какого-нибудь проекта на гитхабе(тенденция). Всё таки лучший пример это конкретный QtCreator-проект. Я не знаю, может вам надо чтобы мы почаще обращались к вашей статье, но всё равно большое спасибо.
Админ, что ты будешь делать, если у тебя в проекте окажется несколько десятков файлов *.cpp, *.h, разбросанных по разным директориям? Я пытался прописать в таком формате
…
INCLUDEPATH += foo_1/include/*.h \
foo_2/include/*.h \
SOURCES += foo_1/src/*.cpp \
foo_2/src/*.cpp \
…
но при парсинге .pro файла qt выдавал ошибку, что нет таких файлов. Некогда тогда было искать решение, пришлось руками прописать каждый файлик. Это было оч неудобно. Есть какое-нибудь решение этого вопроса?
Здравствуйте. Существует недокументированная функция qmake - $$files. Ваш код можно переписать с ее помощью следующим образом:
…
HEADERS += $$files(foo_1/include/*.h) \
$$files(foo_2/include/*.h)
SOURCES += $$files(foo_1/src/*.cpp) \
$$files(foo_2/src/*.cpp)
…
При этом для включения заголовочных файлов в проект достаточно обойтись INCLUDEPATH с указанием имени каталога без перечисления отдельных имен файлов.
export LD_LIBRARY_PATH=../lib.linux/:../lib.linux/import_dir/
в свете данного примера, тут видимо имелось ввиду
export LD_LIBRARY_PATH=../../lib.linux/:../../lib.linux/import_dir/
не так ли?
Zugr:
export LD_LIBRARY_PATH=../lib.linux/:../lib.linux/import_dir/
в свете данного примера, тут видимо имелось ввиду
export LD_LIBRARY_PATH=../../lib.linux/:../../lib.linux/import_dir/
не так ли?
Спасибо за комментарий. Внес поправку в текст статьи.
Нужно отметить, что если нет необходимости, qmake вообще лучше не использовать в качестве сборочной системы.
cmake куда гибче и проще.
У меня нужда появилась, и выяснилось, что почему-то он сам дописывает в название библиотеки её версию. причём не 0.0.1, а просто 0. И линковщик по имени без версии её не находит.
Очень благодарен Вам за такую полезную статью, а также авторам комментариев за не менее ценную информацию!






Anonymous
А можно где-то посмотреть исходный код проекта с описанной в статье структурой?