Мы уже немного успели поработать с OpenCV. В этот раз займемся установкой дополнительных компонентов и разработаем простое приложение, которое использует некоторые из них. С его помощью мы сможем находить фиксированные объекты на изображениях, используя алгоритмы SURF и FLANN:

Для работы с некоторыми расширенными возможностями OpenCV 3.0+ требуется установка дополнительных компонентов из репозитория opencv_contrib. Если они вам потребовались, то проще всего воспользоваться рекомендуемым методом и пересобрать OpenCV целиком.
Мы уже рассматривали процесс сборки OpenCV для Linux и Windows. Чтобы установить дополнительные компоненты, сначала необходимо клонировать Git-репозиторий opencv_contrib себе на диск. Например, я клонировал его по соседству с клоном репозитория opencv.
Далее сборка "чистого" OpenCV от "расширенного" отличается лишь на Шаге 2 (см. статьи по сборке OpenCV под Linux и Windows). К команде cmake мы добавляем дополнительный параметр:
-D OPENCV_EXTRA_MODULES_PATH=<путь_к_opencv_contrib>/modulesНапример, если вы следовали моим рекомендациям относительно структуры каталогов, то параметр может выглядеть следующим образом:
-D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modulesВ широком смысле с помощью SURF и FLANN мы можем решить задачу поиска фиксированного изображения (сохраняющего форму и все свои внешние признаки, но не обязательно угол поворота), которое назовем объектом, на другом изображении (назовем сценой). И приложение, которое мы сейчас создадим, потенциально позволит решать ее именно в таком виде, но с некоторыми оговорками, которые зависят от множества факторов. Однако мы не станем вдаваться в теоретические подробности, а просто воспользуемся технологией.

Для тестирования приложения в качестве объекта я использовал изображение дорожного знака STOP, хотя вы вполне можете попробовать любые другие объекты.
А в качестве сцены удобно использовать изображение с несколькими дорожными знаками. Ведь нам важно, чтобы искомый объект не просто находился там, где он есть, но и не был обнаружен там, где его никогда не было.

За основу возьмем пример из официальной документации OpenCV. Но сначала подготовим pro-файл. Основная часть, которая нас интересует:
win32 {
INCLUDEPATH += C:/OpenCV/include/
LIBS += -LC:/OpenCV/x86/mingw/bin/
OPENCV_VER = 320
}
linux-g++ {
INCLUDEPATH += $$(HOME)/OpenCV/include/
LIBS += -L$$(HOME)/OpenCV/lib/
}
LIBS += -lopencv_core$${OPENCV_VER} \
-lopencv_imgproc$${OPENCV_VER} \
-lopencv_imgcodecs$${OPENCV_VER} \
-lopencv_highgui$${OPENCV_VER} \
-lopencv_flann$${OPENCV_VER} \
-lopencv_calib3d$${OPENCV_VER} \
-lopencv_features2d$${OPENCV_VER} \
-lopencv_xfeatures2d$${OPENCV_VER}
Здесь мы подключаем все необходимые зависимости от OpenCV. Обратите внимание, что вам может потребоваться немного поменять пути к директориям OpenCV, если они у вас отличаются.
Реализация в файле main.cpp:
#include <QApplication>
#include <QFileDialog>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/calib3d.hpp>
#include <opencv2/xfeatures2d.hpp>
using namespace cv;
int main( int argc, char** argv ) {
QApplication app( argc, argv );
static const QString IMAGE_FILES_TMPL = "Images (*.png *.jpg *.jpeg)";
QString objFileName = QFileDialog::getOpenFileName( 0, "Object image", ".", IMAGE_FILES_TMPL );
if( objFileName.isEmpty() ) {
return -1;
}
QString sceneFileName = QFileDialog::getOpenFileName( 0, "Scene image", ".", IMAGE_FILES_TMPL );
if( sceneFileName.isEmpty() ) {
return -2;
}
Mat objImage = imread( objFileName.toStdString(), CV_LOAD_IMAGE_GRAYSCALE );
Mat sceneImage = imread( sceneFileName.toStdString(), CV_LOAD_IMAGE_GRAYSCALE );
if( !objImage.data || !sceneImage.data ) {
return -3;
}
// Шаг 1: Найдем ключевые точки с помощью SURF-детектора
static const int MIN_HESSIAN = 800;
Ptr< xfeatures2d::SurfFeatureDetector > detector = xfeatures2d::SURF::create( MIN_HESSIAN );
std::vector< KeyPoint > objKeypoints, sceneKeypoints;
detector->detect( objImage, objKeypoints );
detector->detect( sceneImage, sceneKeypoints );
// Шаг 2: Высчитаем описатели или дескрипторы (векторы характерстик)
Ptr< xfeatures2d::SurfDescriptorExtractor > extractor = xfeatures2d::SurfDescriptorExtractor::create();
Mat objDescriptors, sceneDescriptors;
extractor->compute( objImage, objKeypoints, objDescriptors );
extractor->compute( sceneImage, sceneKeypoints, sceneDescriptors );
// Шаг 3: Сопоставим векторы дескрипторов с помощью FLANN
FlannBasedMatcher matcher;
std::vector< DMatch > matches;
matcher.match( objDescriptors, sceneDescriptors, matches );
double max_dist = 0;
double min_dist = 100;
// Найдем максимальное и минимальное расстояние между ключевыми точками
for( int i = 0; i < objDescriptors.rows; i++ ) {
double dist = matches[i].distance;
if( dist < min_dist ) {
min_dist = dist;
}
if( dist > max_dist ) {
max_dist = dist;
}
}
// Нарисуем только "хорошие" совпадения (т.е. те, для которых расстояние меньше, чем 3*min_dist)
std::vector< DMatch > goodMatches;
for( int i = 0; i < objDescriptors.rows; i++ ) {
if( matches[ i ].distance < 3 * min_dist ) {
goodMatches.push_back( matches[ i ] );
}
}
Mat imgMatches;
drawMatches( objImage, objKeypoints, sceneImage, sceneKeypoints,
goodMatches, imgMatches, Scalar::all( -1 ), Scalar::all( -1 ),
std::vector< char >(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
// Найдем объект на сцене
std::vector< Point2f > obj;
std::vector< Point2f > scene;
for( size_t i = 0; i < goodMatches.size(); i++ ) {
// Отбираем ключевые точки из хороших совпадений
obj.push_back( objKeypoints[ goodMatches[ i ].queryIdx ].pt );
scene.push_back( sceneKeypoints[ goodMatches[ i ].trainIdx ].pt );
}
Mat H = findHomography( obj, scene, CV_RANSAC );
// Занесем в вектор углы искомого объекта
std::vector< Point2f > objCorners( 4 );
objCorners[ 0 ] = cvPoint( 0, 0 );
objCorners[ 1 ] = cvPoint( objImage.cols, 0 );
objCorners[ 2 ] = cvPoint( objImage.cols, objImage.rows );
objCorners[ 3 ] = cvPoint( 0, objImage.rows );
std::vector< Point2f > sceneCorners( 4 );
perspectiveTransform( objCorners, sceneCorners, H );
// Нарисуем линии между углами (отображение искоромого объекта на сцене)
line( imgMatches, sceneCorners[ 0 ] + Point2f( objImage.cols, 0 ), sceneCorners[ 1 ] + Point2f( objImage.cols, 0 ), Scalar( 0, 255, 0 ), 4 );
line( imgMatches, sceneCorners[ 1 ] + Point2f( objImage.cols, 0 ), sceneCorners[ 2 ] + Point2f( objImage.cols, 0 ), Scalar( 0, 255, 0 ), 4 );
line( imgMatches, sceneCorners[ 2 ] + Point2f( objImage.cols, 0 ), sceneCorners[ 3 ] + Point2f( objImage.cols, 0 ), Scalar( 0, 255, 0 ), 4 );
line( imgMatches, sceneCorners[ 3 ] + Point2f( objImage.cols, 0 ), sceneCorners[ 0 ] + Point2f( objImage.cols, 0 ), Scalar( 0, 255, 0 ), 4 );
// Покажем найденные совпадения
imshow( "Good Matches & Object detection", imgMatches );
waitKey( 0 );
return 0;
}
В целом код не должен вызывать сложностей и местами дополнен комментариями, но еще раз кратко пройдемся по основным шагам:
В результате получаем:
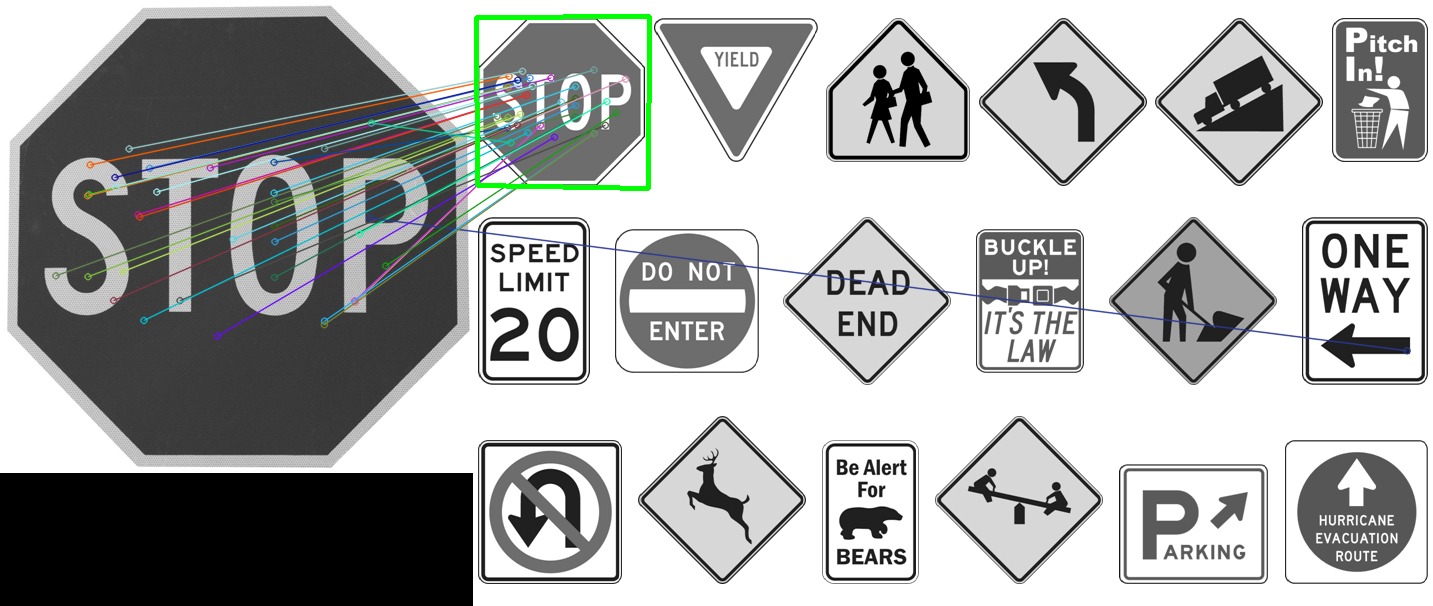
Скачать пример использования модулей OpenCV - SURF и FLANN
Здравствуйте. Спасибо за комментарий.
Очень интересная тема для новой статьи. В ближайшее время займусь подготовкой материала.
Добрый день!
Ваш материал, просто замечательный. У меня на Mac нет такой библиотеки xfeatures2d. Когда я устанавливаю opencv_contrib/modules, то после сборки не нахожу xfeatures2d. Может он только под Linux и Windows? Спасибо за помощь.
Anonymous:
Добрый день!
Ваш материал, просто замечательный. У меня на Mac нет такой библиотеки xfeatures2d. Когда я устанавливаю opencv_contrib/modules, то после сборки не нахожу xfeatures2d. Может он только под Linux и Windows? Спасибо за помощь.
Здравствуйте. Спасибо за комментарий! К сожалению, у меня нет возможности проверить сборку под Mac.
А как Вы выполняете установку? В гит-репозитории проекта модули доступны, и в теории должны работать под любой ОС.
По идее, особых отличий под Mac быть не должно, но, как уже говорил, у меня под рукой его нет, поэтому сам проверить не могу.





Anonymous
Доброго времени суток!
Есть предложение рассмотреть цветовую модель HSV. Точнее, ее применимость к распознаванию объектов по цвету с использованием библиотеки OpenCV. Особенно интересует распознавание оттенков цвета в каком-то диапазоне. Допустим "красного платья целиком". Глаз то распознает уверенно, а вот камера даст массив точек разного оттенка.